Команда исследователей из Вашингтонского университета разработала «умные» наушники на базе искусственного интеллекта, получившие название Target Speech Hearing. Надевшему их пользователю достаточно в течение нескольких секунд посмотреть на собеседника, после чего он будет слышать только его голос, а остальные голоса и посторонние звуки будут заглушены.
Перспективное решение было впервые представлено 14 мая в Гонолулу на конференции «Человеческий фактор в компьютерных системах», где авторы поделились подробностями о проекте и исходными данными, на основании которых сторонние разработчики могут проектировать свои собственные устройства. В основу Target Speech Hearing легли две ключевые технологические тенденции - шумоподавление и машинное обучение. Современные алгоритмы шумоподавления способны эффективно устранять окружающие звуки, но заглушать их избирательно, удаляя нежелательные и оставляя необходимые, они пока не умеют. Идея применения для этого искусственного интеллекта уже не нова. Ряд систем использует его, чтобы точнее определять наличие посторонних звуков, но для этого им требуются предварительно записанные образцы, на основании которых и происходит распознавание.
Созданная командой исследователей технология способна в реальном времени регистрировать образец голоса говорящего, а затем удалять из аудиотракта все остальные звуки, причем в отличие от других схожих разработок осуществлять регистрацию она может даже в шумной среде со множеством голосов и посторонних звуков. Представленный прототип разработан на базе гарнитуры с шумоподавлением Sony WH-1000XM4, пары бинауральных микрофонов Sonic Presence SP15C и микрокомпьютера Orange Pi 5B с предустановленным программным обеспечением. Чтобы система внесла в свою базу образец речи, достаточно нажать кнопку и в течение трех-пяти секунд смотреть на говорящего. Встроенные в каждую из чаш наушников микрофоны записывают бинауральный звук, после чего нейронная сеть производит анализ его характеристик.
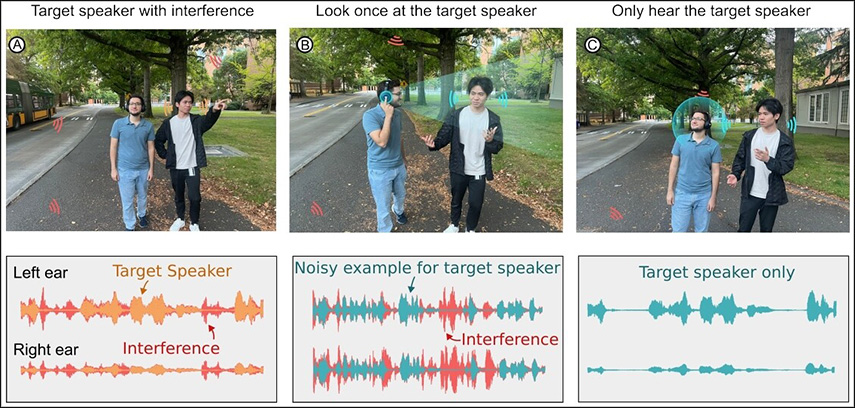
Применение бинауральной системы позволяет точно определить какой именно голос требуется взять за образец, так как в тот момент, когда пользователь смотрит на говорящего, его речь одновременно захватывается обоими микрофонами, в то время, как речь со стороны будет достигать одного и второго микрофона за разное время. Из-за того, что говорящий может не всегда идеально точно находиться посередине между двумя микрофонами, допускается погрешность в 16°. Выделенный таким образом из общего звукового фона голос поступает в другую нейронную сеть, которая в реальном времени анализируется захватываемые микрофонами звуки и заглушает все, отличающиеся по своим характеристикам от зарегистрированного прежде образца.
В дальнейшем пользователю больше не нужно смотреть на говорящего. Он может произвольно перемещаться, двигать головой и выполнять любые другие действия, продолжая слышать выбранный голос. Среднее время обработки аудиофрагментов длительностью 8 мс у разработанной исследователями модели составляет 6,2 мс, а общая сквозная задержка находится на уровне 18,24 мс, что делает ее системой реального времени.
Представленный прототип способен регистрировать только одного говорящего. Основным условием для точности детектирования является отсутствие другого громкого голоса, доносящегося с того же направления, что и целевой голос. Если пользователя не устраивает качество звука, то он может провести повторную регистрацию. Target Speech Hearing была успешно протестирована на 21 испытуемом. Все они отметили, что четкость голоса в сравнении с прослушиванием речи собеседника в шумной среде без дополнительной обработки повысилась почти в два раза. В дальнейшем разработчики планируют реализовать систему не только в полноразмерных наушниках, но и в наушниках-вкладышах и слуховых аппаратах.
Комментирует главный автор проекта Шьям Голлакота, профессор Вашингтонского университета:
«Сегодня многие склонны думать об искусственном интеллекте как о чат-ботах, которые отвечают на вопросы, но этим сфера его применений не ограничиваются. В своем проекте мы разрабатываем ИИ, способный изменить слуховое восприятие с учетом предпочтений пользователя. Благодаря Target Speech Hearing вы можете четко слышать одного говорящего, даже если находитесь в шумной обстановке, где разговаривает множество других людей».